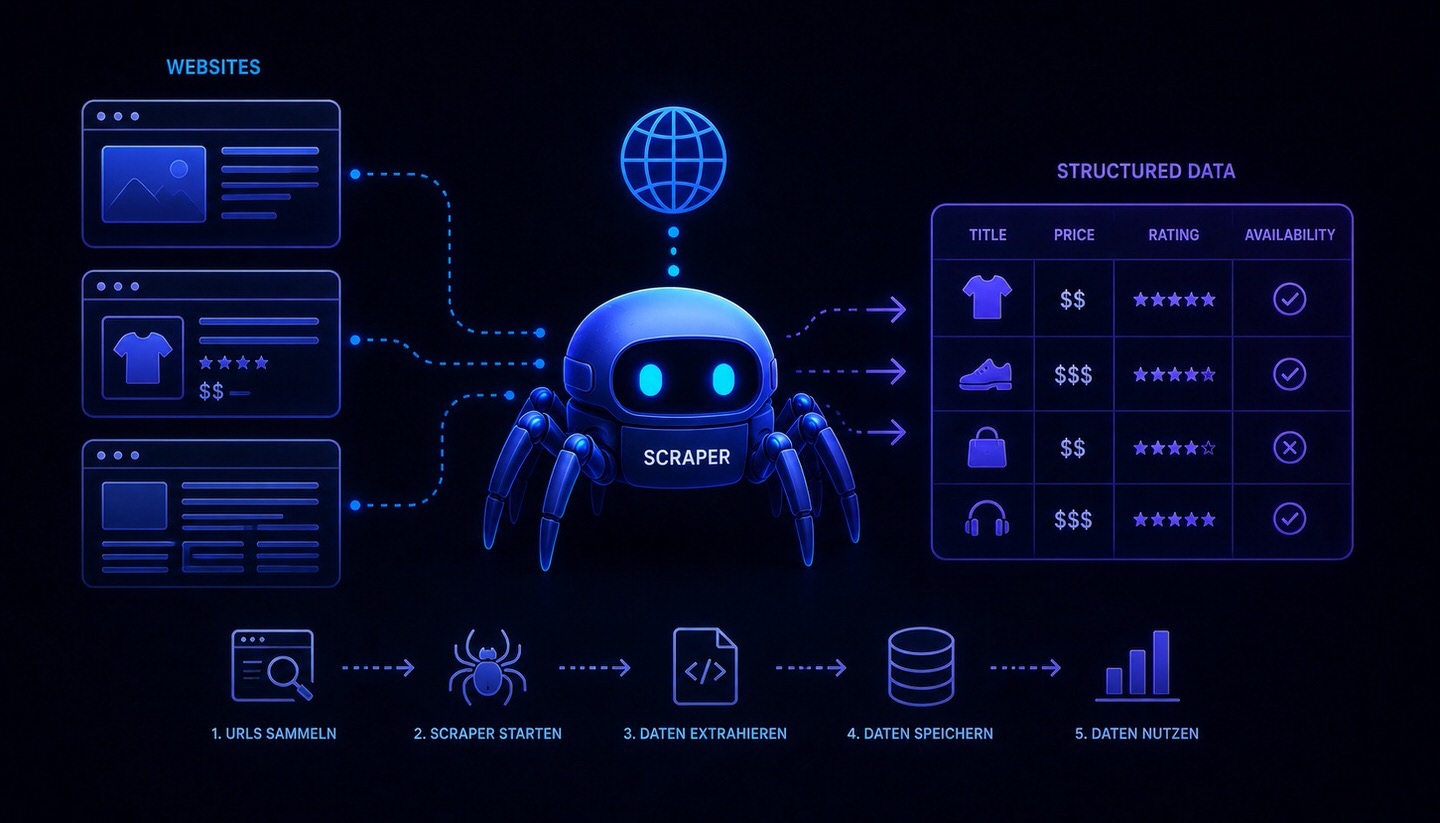
Web Scraping
Web scraping automatycznie pobiera dane z witryn internetowych - przydatne w SEO, porównaniach cen czy AI, ale prawnie złożone.
Czym jest web scraping?
Web scraping (znany również jako web harvesting lub data scraping, po polsku mniej więcej "zbieranie danych") oznacza automatyczne odczytywanie i ekstrakcję danych ze stron internetowych za pomocą oprogramowania lub botów. Program do scrapingu odwiedza strony internetowe, odczytuje ich zawartość i wyodrębnia konkretne informacje, takie jak ceny, dane produktów, teksty czy dane kontaktowe, a następnie zapisuje je w ustrukturyzowanym formacie, np. w tabeli lub bazie danych. To, co człowiek musiałby żmudnie kopiować ręcznie, scraper wykonuje automatycznie i na dużą skalę.
Web scraping jest przede wszystkim neutralną techniką, która może być wykorzystywana zarówno do pożytecznych, jak i problematycznych celów. Dla Twojej grupy docelowej temat ten jest istotny z dwóch powodów: jako narzędzie, które można samodzielnie wykorzystać, oraz jako potencjalne zagrożenie, które może dotyczyć własnej strony internetowej.
Web scraping a crawling: różnice
Web scraping jest często mylony z crawlingiem przez web crawlery. Oba wykorzystują zautomatyzowane programy, ale mają różne cele:
- Crawling: Służy do odkrywania i indeksowania stron. Web crawler podąża za linkami, aby znaleźć jak najwięcej stron i przygotować je do indeksu.
- Scraping: Służy do celowego wyodrębniania określonych danych ze stron. Chodzi tu nie o odkrywanie, lecz o pobieranie konkretnych informacji.
Uproszczając: Crawling pyta "Jakie strony istnieją?", scraping pyta "Jakie konkretne dane znajdują się na tych stronach?". W praktyce oba procesy często się pokrywają, ponieważ scraper musi najpierw znaleźć strony, zanim wyodrębni dane.
Do czego wykorzystuje się web scraping?
Istnieje wiele legalnych zastosowań, na przykład:
- Porównywarki cen i monitorowanie rynku: Portale porównujące zbierają ceny i oferty z wielu stron internetowych.
- Narzędzia SEO: Wiele narzędzi analitycznych wykorzystuje scraping do analizy wyników wyszukiwania, konkurencji czy backlinków.
- Agregatory: Platformy, które gromadzą np. oferty pracy, nieruchomości czy oferty podróży.
- Badania i analiza danych: Zbieranie dużych zbiorów danych do analiz.
- Trening modeli AI: Duże modele językowe są trenowane m.in. na treściach zebranych z sieci.
Kiedy web scraping staje się problematyczny?
Ta sama technika może być również wykorzystywana w sposób nieetyczny, np.:
- Kradzież treści: Odczytywanie i nieautoryzowane publikowanie cudzych treści, co prowadzi do problemów z duplikacją treści (duplicate content) i naruszeniem praw autorskich.
- Pobieranie danych osobowych: Masowe zbieranie danych, takich jak adresy e-mail, co jest wątpliwe z punktu widzenia ochrony danych.
- Przeciążenie serwera: Agresywny scraping może mocno obciążyć serwery strony internetowej.
- Spam: Zbieranie danych kontaktowych do niechcianej reklamy.
Web scraping z perspektywy SEO
Dla właścicieli stron internetowych temat ten jest istotny z dwóch punktów widzenia:
- Własne treści są scrapowane: Jeśli własne teksty są odczytywane i publikowane gdzie indziej, powstaje zewnętrzny duplicate content. Zazwyczaj Google rozpoznaje oryginalne źródło, więc zwykle to oryginalna strona, a nie kopia, pojawia się w wynikach wyszukiwania. Mimo to może to być irytujące i w rzadkich przypadkach powodować problemy.
- Treści dla wyszukiwarek AI: Również systemy AI zbierają treści z sieci. Pojawia się tu pytanie, czy chcemy, aby nasze treści były dostępne do trenowania lub wykorzystywania przez systemy AI. Podobnie jak w przypadku klasycznych crawlerów, można to kontrolować za pomocą pliku robots.txt, co bezpośrednio wiąże się z tematem GEO.
Legalna alternatywa: interfejsy API
Ważna uwaga: tam, gdzie to możliwe, oficjalne interfejsy API są czystszym rozwiązaniem, aby uzyskać dostęp do danych. Wielu dostawców udostępnia swoje dane przez API, które umożliwia kontrolowany, dozwolony i stabilny dostęp. W przeciwieństwie do często prawnie wątpliwego i technicznie niestabilnego scrapingu, korzystanie z API jest wyraźnie przewidziane i tym samym preferowane, jeśli jest dostępne.
Aspekty prawne
Dla Twojej grupy docelowej ważna jest jasna wskazówka: legalność web scrapingu jest złożona i zależy w dużej mierze od konkretnego przypadku, np. od tego, jakie dane są odczytywane, w jaki sposób to się odbywa i jak są one wykorzystywane. Problemami są w szczególności odczytywanie treści chronionych prawem autorskim, zbieranie danych osobowych (z uwzględnieniem RODO) oraz omijanie technicznych środków ochrony lub warunków korzystania ze strony internetowej. Jeśli chcesz wykorzystać scraping, powinieneś dokładnie sprawdzić jego legalność. Ta wskazówka służy jedynie do ogólnej orientacji i nie zastępuje porady prawnej.
Podsumowanie
Web scraping to automatyczne odczytywanie i ekstrakcja danych ze stron internetowych i jest przede wszystkim neutralną techniką. W odróżnieniu od crawlowania, które odkrywa strony, scraping ma na celu celowe wyodrębnianie konkretnych informacji. Ma wiele legalnych zastosowań, od porównywarek cen, przez narzędzia SEO, po trenowanie modeli AI, ale może być również wykorzystywany w sposób nieetyczny do kradzieży treści czy zbierania danych. Dla właścicieli stron internetowych jest to istotne, ponieważ ich treści mogą być scrapowane, czy to do tworzenia kopii, czy do wykorzystania przez systemy AI, co częściowo można kontrolować za pomocą pliku robots.txt. Jeśli dostępne jest oficjalne API, zawsze należy je preferować zamiast scrapingu. Ponieważ sytuacja prawna jest złożona, stosowanie scrapingu powinno być zawsze dokładnie sprawdzone, a w razie wątpliwości skonsultowane z ekspertem.