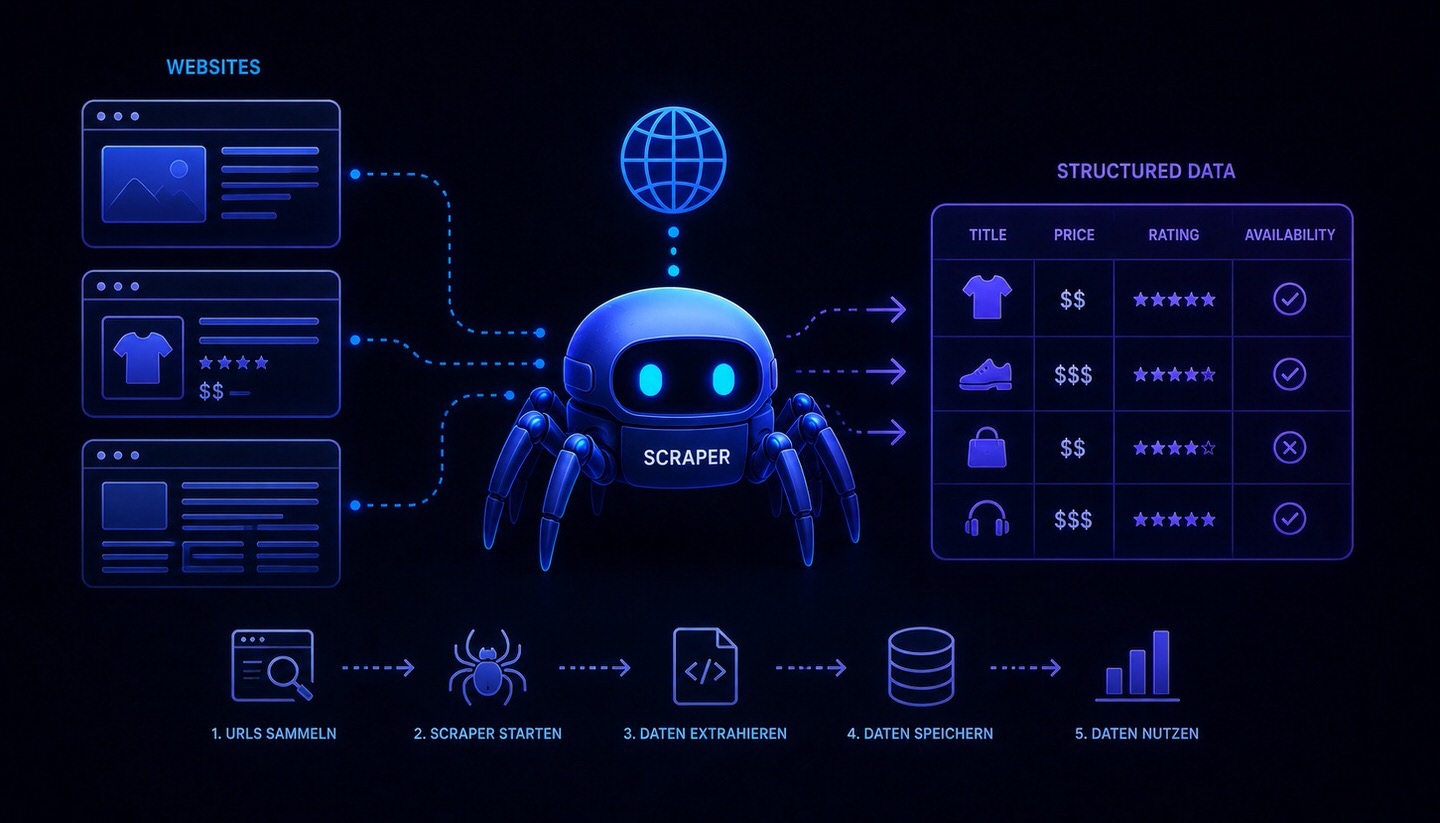
Web Scraping
Web Scraping extrahiert automatisiert Daten aus Webseiten - nützlich für SEO, Preisvergleiche oder KI, aber rechtlich komplex.
Was ist Web Scraping?
Web Scraping (auch Web Harvesting oder Daten-Scraping, auf Deutsch etwa "Daten abschöpfen") bezeichnet das automatisierte Auslesen und Extrahieren von Daten aus Webseiten mithilfe von Software oder Bots. Ein Scraping-Programm ruft dabei Webseiten auf, liest deren Inhalte und filtert gezielt bestimmte Informationen heraus, etwa Preise, Produktdaten, Texte oder Kontaktangaben, und speichert diese in einem strukturierten Format wie einer Tabelle oder Datenbank. Was ein Mensch sonst mühsam von Hand kopieren würde, erledigt ein Scraper automatisch und in großem Umfang.
Web Scraping ist zunächst eine neutrale Technik, die sowohl für nützliche als auch für problematische Zwecke eingesetzt werden kann. Für deine Zielgruppe ist das Thema in zweierlei Hinsicht relevant: als Werkzeug, das man selbst nutzen kann, und als möglicher Eingriff, von dem die eigene Webseite betroffen sein kann.
Web Scraping und Crawling: der Unterschied
Web Scraping wird leicht mit dem Crawling durch Webcrawler verwechselt. Beide nutzen automatisierte Programme, verfolgen aber unterschiedliche Ziele:
- Crawling: Dient dem Entdecken und Erfassen von Seiten. Ein Webcrawler folgt Links, um möglichst viele Seiten zu finden und für einen Index vorzubereiten.
- Scraping: Dient dem gezielten Extrahieren bestimmter Daten aus Seiten. Hier geht es nicht ums Entdecken, sondern um das Herausziehen konkreter Informationen.
Vereinfacht: Crawling fragt "Welche Seiten gibt es?", Scraping fragt "Welche konkreten Daten stehen auf diesen Seiten?". In der Praxis überschneiden sich beide oft, da ein Scraper zunächst Seiten finden muss, bevor er Daten extrahiert.
Wofür wird Web Scraping genutzt?
Es gibt zahlreiche legitime Anwendungen, etwa:
- Preisvergleiche und Marktbeobachtung: Vergleichsportale sammeln Preise und Angebote von vielen Webseiten.
- SEO-Werkzeuge: Viele Analyse-Tools nutzen Scraping, um Suchergebnisse, Wettbewerber oder Backlinks auszuwerten.
- Aggregatoren: Plattformen, die etwa Stellenanzeigen, Immobilien oder Reiseangebote bündeln.
- Forschung und Datenanalyse: Das Sammeln großer Datenmengen für Auswertungen.
- Training von KI-Modellen: Große Sprachmodelle werden unter anderem mit im Web gesammelten Inhalten trainiert.
Wann wird Web Scraping problematisch?
Dieselbe Technik kann auch missbräuchlich eingesetzt werden, etwa:
- Inhaltsdiebstahl: Das Auslesen und unerlaubte erneute Veröffentlichen fremder Inhalte, was zu Problemen mit doppelten Inhalten (Duplicate Content) und Urheberrechtsverletzungen führt.
- Abgreifen personenbezogener Daten: Das massenhafte Sammeln von Daten wie E-Mail-Adressen, was datenschutzrechtlich heikel ist.
- Serverüberlastung: Aggressives Scraping kann die Server einer Webseite stark belasten.
- Spam: Das Sammeln von Kontaktdaten für unerwünschte Werbung.
Web Scraping aus SEO-Sicht
Für Webseitenbetreiber ist das Thema aus zwei Blickwinkeln relevant:
- Die eigenen Inhalte werden gescrapt: Werden eigene Texte ausgelesen und anderswo erneut veröffentlicht, entsteht externer Duplicate Content. In der Regel erkennt Google jedoch die ursprüngliche Quelle, sodass meist die Originalseite und nicht die Kopie rankt. Trotzdem kann es ärgerlich sein und in seltenen Fällen Probleme bereiten.
- Inhalte für die KI-Suche: Auch KI-Systeme sammeln Webinhalte. Hier stellt sich die Frage, ob man möchte, dass die eigenen Inhalte für das Training oder die Nutzung durch KI-Systeme zugänglich sind. Dies lässt sich, ähnlich wie bei klassischen Crawlern, über die robots.txt steuern, was direkt mit dem Thema GEO zusammenhängt.
Die legitime Alternative: Schnittstellen (APIs)
Ein wichtiger Punkt: Wo immer möglich, ist eine offizielle Schnittstelle (API) der sauberere Weg, um an Daten zu gelangen. Viele Anbieter stellen ihre Daten über eine API bereit, die einen kontrollierten, erlaubten und stabilen Zugriff ermöglicht. Im Gegensatz zum oft rechtlich heiklen und technisch fragilen Scraping ist die Nutzung einer API ausdrücklich vorgesehen und damit die bevorzugte Lösung, wenn sie verfügbar ist.
Rechtliche Einordnung
Für deine Zielgruppe ist ein klarer Hinweis wichtig: Die rechtliche Zulässigkeit von Web Scraping ist komplex und hängt stark vom Einzelfall ab, etwa davon, welche Daten ausgelesen werden, wie das geschieht und wie sie verwendet werden. Heikel sind insbesondere das Auslesen urheberrechtlich geschützter Inhalte, das Sammeln personenbezogener Daten (mit Blick auf die DSGVO) sowie das Übergehen technischer Schutzmaßnahmen oder der Nutzungsbedingungen einer Webseite. Wer Scraping einsetzen möchte, sollte die rechtliche Zulässigkeit daher sorgfältig prüfen. Dieser Hinweis dient der Einordnung und ersetzt keine Rechtsberatung.
Fazit
Web Scraping ist das automatisierte Auslesen und Extrahieren von Daten aus Webseiten und zunächst eine neutrale Technik. Im Unterschied zum Crawling, das Seiten entdeckt, zielt Scraping auf das gezielte Herausziehen konkreter Informationen. Es hat viele legitime Anwendungen, von Preisvergleichen über SEO-Werkzeuge bis zum Training von KI-Modellen, kann aber auch missbräuchlich für Inhaltsdiebstahl oder das Sammeln von Daten eingesetzt werden. Für Webseitenbetreiber ist es relevant, weil die eigenen Inhalte gescrapt werden können, sei es für Kopien oder für KI-Systeme, was sich über die robots.txt teils steuern lässt. Wo eine offizielle Schnittstelle (API) verfügbar ist, ist diese dem Scraping stets vorzuziehen. Und da die rechtliche Lage komplex ist, sollte der Einsatz von Scraping immer sorgfältig und im Zweifel mit fachkundiger Beratung geprüft werden.