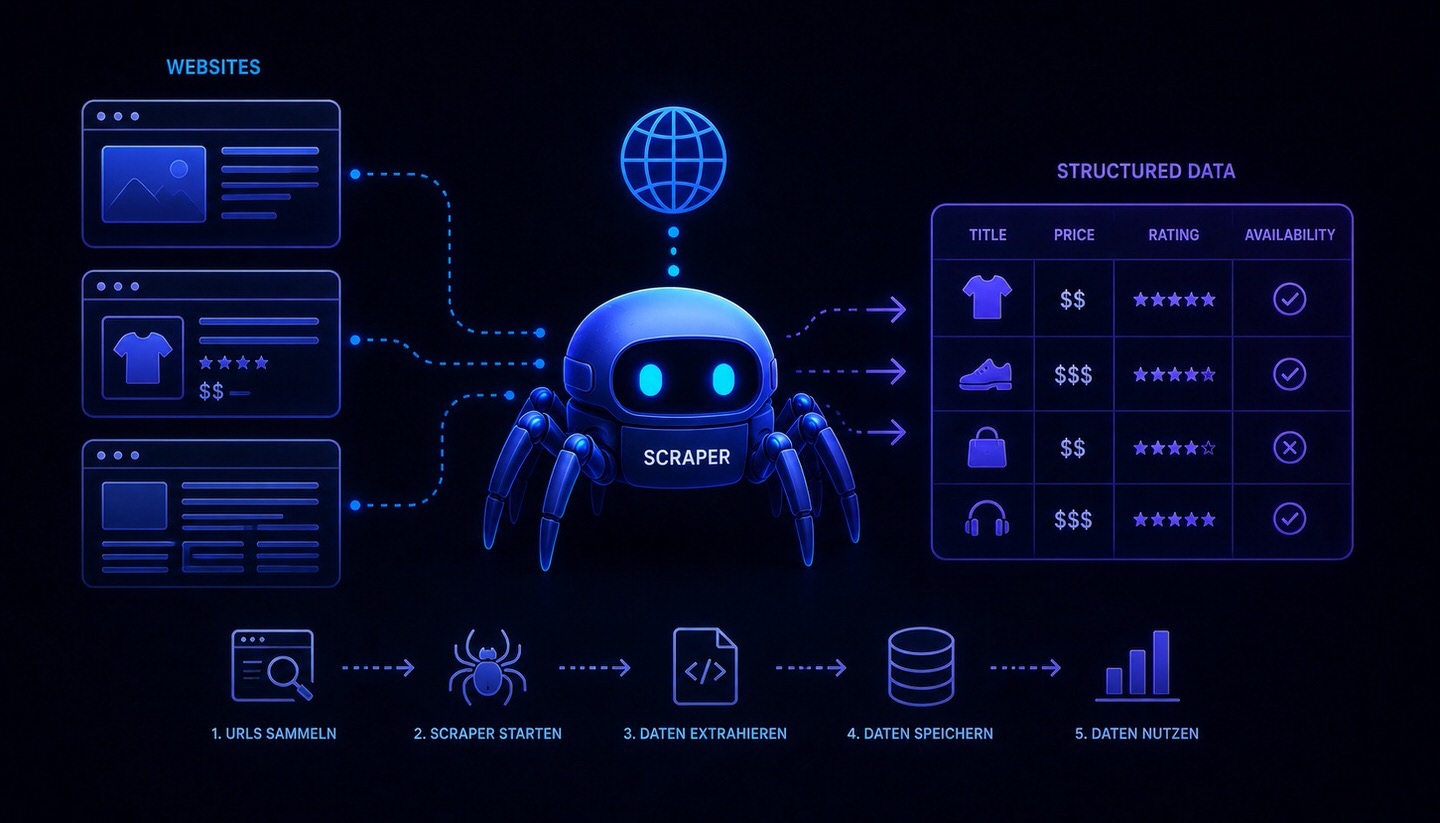
Web Scraping
Web scraping automatically extracts data from websites - useful for SEO, price comparisons, or AI, but legally complex.
What is Web Scraping?
Web Scraping (also known as Web Harvesting or Data Scraping) refers to the automated reading and extraction of data from websites using software or bots. A scraping program accesses websites, reads their content, and filters out specific information such as prices, product data, texts, or contact details, saving it in a structured format like a table or database. What a person would otherwise laboriously copy by hand, a scraper accomplishes automatically and on a large scale.
Web Scraping is initially a neutral technique that can be used for both useful and problematic purposes. For your target audience, the topic is relevant in two ways: as a tool that can be used themselves, and as a potential intrusion that their own website could be affected by.
Web Scraping and Crawling: The Difference
Web Scraping is often confused with crawling by web crawlers. Both use automated programs but pursue different goals:
- Crawling: Serves to discover and capture pages. A web crawler follows links to find as many pages as possible and prepare them for an index.
- Scraping: Serves the targeted extraction of specific data from pages. Here, the focus is not on discovery but on extracting concrete information.
Simply put: Crawling asks "Which pages exist?", while Scraping asks "What specific data is on these pages?". In practice, both often overlap, as a scraper must first find pages before it can extract data.
What is Web Scraping Used For?
There are numerous legitimate applications, such as:
- Price comparisons and market monitoring: Comparison portals collect prices and offers from many websites.
- SEO tools: Many analysis tools use scraping to evaluate search results, competitors, or backlinks.
- Aggregators: Platforms that bundle job listings, real estate, or travel offers.
- Research and data analysis: Collecting large amounts of data for evaluations.
- Training AI models: Large language models are trained, among other things, with content collected from the web.
When Does Web Scraping Become Problematic?
The same technique can also be misused, for example:
- Content theft: Extracting and republishing third-party content without permission, leading to issues with duplicate content and copyright infringement.
- Collecting personal data: Mass collection of data such as email addresses, which is legally sensitive under data protection regulations.
- Server overload: Aggressive scraping can heavily strain a website’s servers.
- Spam: Collecting contact data for unwanted advertising.
Web Scraping from an SEO Perspective
For website operators, the topic is relevant from two perspectives:
- Your own content is scraped: If your own texts are extracted and republished elsewhere, external duplicate content is created. Generally, Google recognizes the original source, so usually the original page and not the copy ranks. Nevertheless, it can be annoying and, in rare cases, cause problems.
- Content for AI search: AI systems also collect web content. This raises the question of whether you want your content to be accessible for training or use by AI systems. Similar to traditional crawlers, this can be controlled via the robots.txt, which is directly related to the topic of GEO.
The Legitimate Alternative: Interfaces (APIs)
An important point: Wherever possible, an official interface (API) is the cleaner way to obtain data. Many providers offer their data via an API, which enables controlled, permitted, and stable access. In contrast to the often legally questionable and technically fragile scraping, using an API is explicitly intended and thus the preferred solution when available.
Legal Classification
For your target audience, an important note: The legal permissibility of web scraping is complex and highly dependent on the specific case, such as which data is extracted, how it is done, and how it is used. Particularly sensitive are the extraction of copyrighted content, the collection of personal data (with regard to the GDPR), and bypassing technical protection measures or a website’s terms of use. Anyone wishing to use scraping should therefore carefully check its legal permissibility. This note serves as an overview and does not replace legal advice.
Conclusion
Web Scraping is the automated extraction of data from websites and is initially a neutral technique. Unlike crawling, which discovers pages, scraping aims to extract specific information. It has many legitimate applications, from price comparisons and SEO tools to training AI models, but can also be misused for content theft or data collection. For website operators, it is relevant because their own content can be scraped, whether for copies or for AI systems, which can partly be controlled via the robots.txt. Where an official interface (API) is available, this is always preferable to scraping. And since the legal situation is complex, the use of scraping should always be carefully reviewed and, in case of doubt, with expert advice.