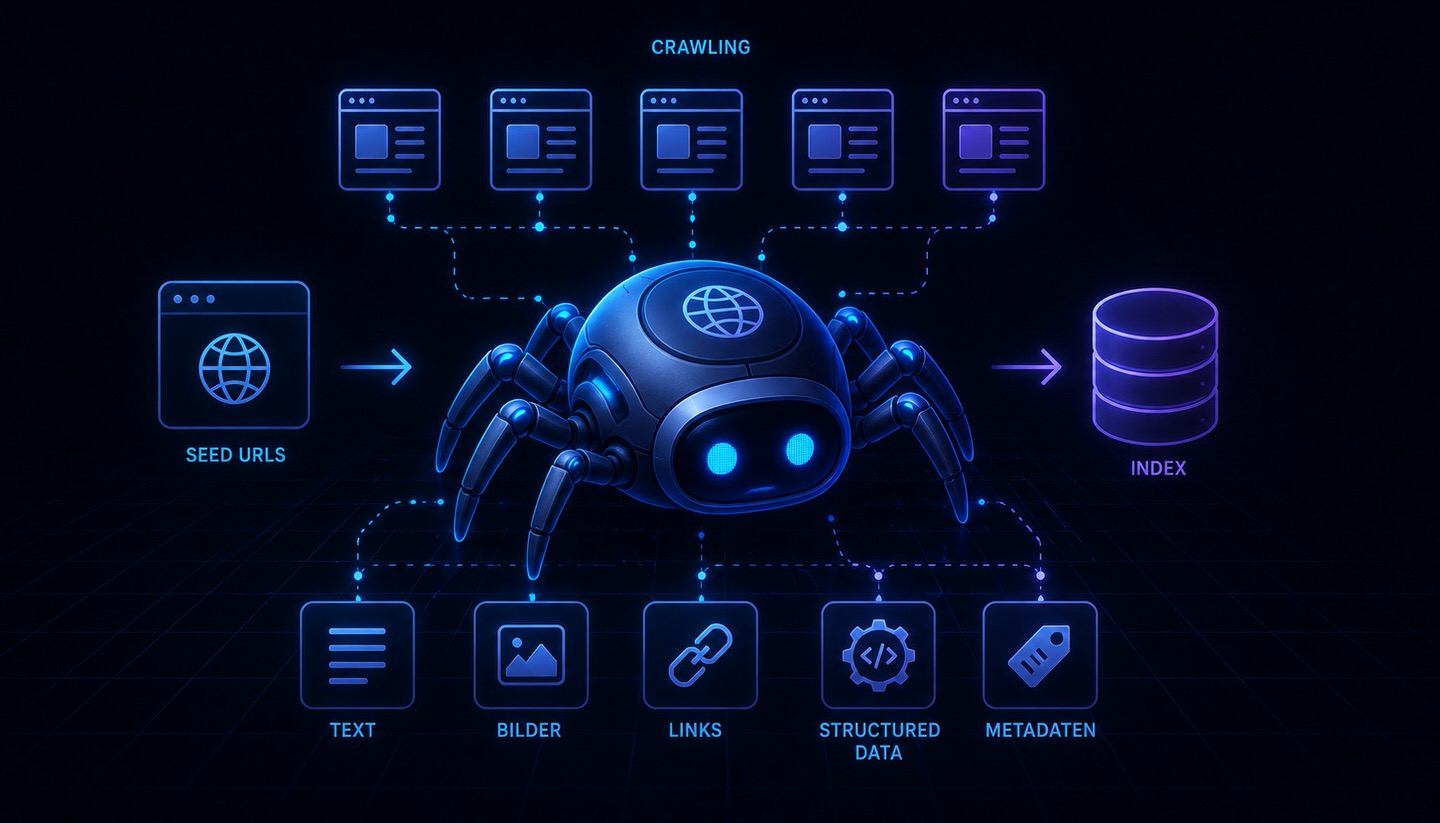
Web crawler
Web crawlery to zautomatyzowane programy przeszukujące internet - kluczowe dla wyszukiwarek i SEO.
Czym jest web crawler?
Web crawler (nazywany również pająkiem, botem, searchbotem lub po prostu crawlerem) to zautomatyzowany program, który systematycznie przeszukuje internet, podążając od strony do strony za linkami i odczytując ich treści. Wyszukiwarki takie jak Google wykorzystują web crawlery, aby odkrywać nowe i zaktualizowane strony internetowe, rejestrować ich zawartość i przygotowywać ją do późniejszego włączenia do indeksu wyszukiwania. Crawler jest więc swego rodzaju zwiadowcą wyszukiwarki, który nieustannie eksploruje sieć.
Nazwy "crawler" (pełzający) i "spider" (pająk) wynikają z tego, że program porusza się po sieci wzdłuż linków, podobnie jak pająk przemieszcza się po swojej sieci. Bez web crawlerów wyszukiwarki nie wiedziałyby, jakie strony w ogóle istnieją w internecie.
Jak działa web crawler?
Działanie crawlera opiera się na prostym, powtarzalnym schemacie:
- Rozpoczęcie od znanych adresów: Crawler zaczyna od listy już znanych adresów URL.
- Odczytanie strony: Pobiera stronę i rejestruje jej zawartość.
- Śledzenie linków: Zbiera linki zawarte na stronie i umieszcza je w kolejce, aby odwiedzić również te strony.
- Powtarzanie: Proces ten powtarza się nieustannie, dzięki czemu crawler krok po kroku przemierza sieć i odkrywa coraz więcej stron.
Zebrane w ten sposób treści są następnie przekazywane do dalszego przetwarzania przez wyszukiwarkę. W tym miejscu konieczne jest ważne rozróżnienie, które często jest mylone.
Crawlowanie, indeksowanie i ranking: trzy różne etapy
Crawlowanie to tylko pierwszy z trzech etapów, które przechodzi wyszukiwarka:
- Crawlowanie: Crawler odkrywa i odczytuje stronę. Nie oznacza to jednak, że pojawi się ona w wynikach wyszukiwania.
- Indeksowanie: Zarejestrowane treści są analizowane, klasyfikowane i dodawane do ogromnego indeksu wyszukiwania.
- Ranking: W odpowiedzi na zapytanie wyszukiwarki, zindeksowane strony są sortowane według trafności i wyświetlane.
Strona musi więc najpierw zostać zcrawlowana, aby mogła być zindeksowana, a dopiero potem może w ogóle uzyskać ranking. Jeśli strona nie zostanie zcrawlowana, pozostanie niewidoczna dla wyszukiwarki.
Znane web crawlery
Najbardziej znanym web crawlerem jest Googlebot, crawler Google. Również inne wyszukiwarki mają swoje własne crawlery, na przykład Bingbot od Bing. Do tego dochodzą liczne inne boty, które przeszukują sieć w różnych celach, na przykład do narzędzi analizy SEO.
Jak sterować web crawlerami?
Właściciele stron internetowych mogą celowo wpływać na zachowanie crawlerów na swojej stronie, co częściowo już znasz z glosariusza:
- robots.txt: Ten plik informuje crawlery, które obszary mogą crawlować, a które nie. Ważne: Zakaz crawlowania nie jest wykluczeniem z indeksu.
- Meta-Robots i X-Robots-Tag: Sterują tym, czy strona ma być indeksowana i czy należy podążać za jej linkami.
- Mapa XML (XML-Sitemap): Rodzaj spisu treści, który pomaga crawlerom znaleźć wszystkie ważne strony.
- Linkowanie wewnętrzne: Ponieważ crawlery podążają za linkami, dobre linkowanie wewnętrzne pomaga w tym, aby wszystkie strony zostały odnalezione.
Budżet crawlowania
Ważnym pojęciem w tym kontekście jest budżet crawlowania. Wyszukiwarki nie crawlują bez ograniczeń każdej strony dowolną ilość razy, lecz rozdzielają swoje zasoby. Szczególnie w przypadku bardzo dużych stron internetowych ważne jest, aby budżet crawlowania nie był marnowany na nieistotne lub zduplikowane strony, lecz był wykorzystywany dla istotnych treści. Pomaga w tym przejrzysta struktura, dobrze utrzymana mapa strony oraz unikanie niepotrzebnych stron.
Web crawlery a wyszukiwanie oparte na AI
Obecny rozwój znacznie poszerza to zagadnienie: obok klasycznych crawlerów wyszukiwarek istnieją dziś również crawlery, które zbierają treści dla systemów AI i dużych modeli językowych, na przykład dla usług odpowiedzi AI. Dla widoczności w wyszukiwaniu wspomaganym przez AI (GEO) jest to niezwykle istotne. Szczególnie ważne są dwa aspekty: po pierwsze, większość tych crawlerów AI nie wykonuje JavaScriptu i odczytuje jedynie czysty kod HTML, dlatego ważne treści powinny znajdować się bezpośrednio w HTML. Po drugie, również te crawlery można kontrolować za pomocą pliku robots.txt, dzięki czemu właściciele stron mogą decydować, czy ich treści mają być dostępne do trenowania lub wykorzystania przez systemy AI.
Podsumowanie
Web crawler to zautomatyzowany program, który systematycznie przeszukuje internet, podążając za linkami i odczytując treści, przede wszystkim Googlebot. Stanowi on pierwszy etap przetwarzania przez wyszukiwarkę: dopiero crawlowanie umożliwia indeksowanie, a tym samym w ogóle ranking. Właściciele stron internetowych mogą celowo sterować crawlowaniem za pomocą pliku robots.txt, dyrektyw meta, mapy XML oraz dobrego linkowania wewnętrznego i powinni zwracać uwagę na efektywny budżet crawlowania, szczególnie w przypadku dużych stron. Wraz z rozwojem wyszukiwania opartego na AI pojawiają się nowe crawlery, które zazwyczaj nie przetwarzają JavaScriptu i również dają się kontrolować. Dbając o to, aby ważne treści były łatwo dostępne i znajdowały się w HTML, tworzy się podstawę dla widoczności zarówno w klasycznym, jak i wspomaganym przez AI wyszukiwaniu.