Web Crawler
Web crawlers are automated programs that scan the internet - essential for search engines and SEO.
What is a Web Crawler?
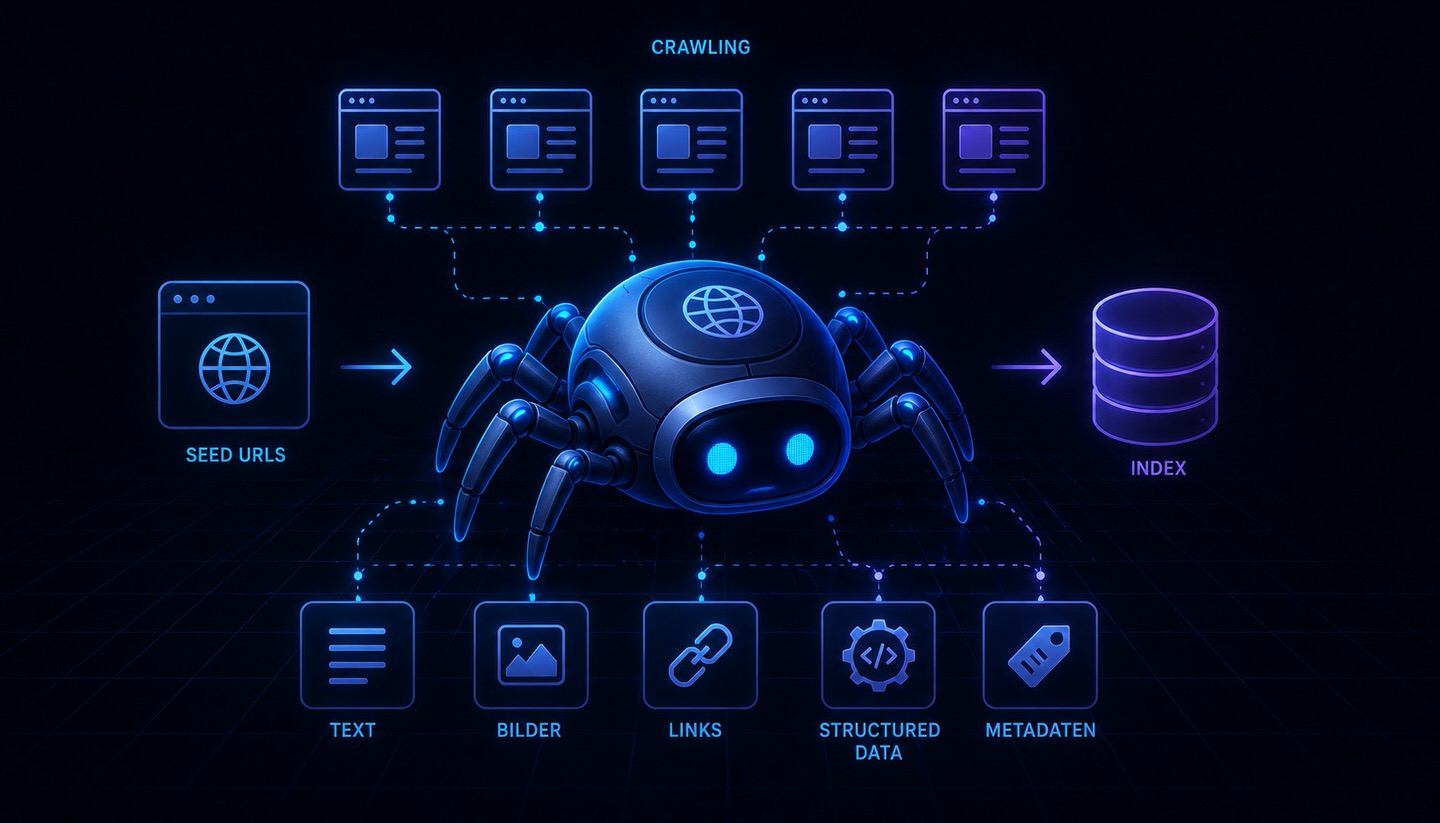
A web crawler (also known as a spider, bot, searchbot, or simply crawler) is an automated program that systematically searches the internet by following links from page to page and reading their content. Search engines like Google use web crawlers to discover new and updated websites, capture their content, and prepare them for later inclusion in the search index. The crawler is, in a sense, the scout of a search engine, continuously exploring the web.
The terms "crawler" and "spider" originate from the way the program moves through the network via links, much like a spider moves through its web. Without web crawlers, search engines would not know which pages exist on the internet at all.
How Does a Web Crawler Work?
A crawler's process follows a simple, repetitive principle:
- Start with known addresses: The crawler begins with a list of already known URLs.
- Read the page: It accesses a page and captures its content.
- Follow links: It collects the links on the page and adds them to a queue to visit those pages as well.
- Repeat: This process repeats continuously, allowing the crawler to work its way through the web step by step and discover more and more pages.
The content collected in this way is then passed on to the search engine for further processing. This is where an important distinction is needed, one that is often confused.
Crawling, Indexing, and Ranking: Three Different Steps
Crawling is just the first of three steps that a search engine goes through:
- Crawling: The crawler discovers and reads a page. However, this does not yet mean that the page will appear in search results.
- Indexing: The captured content is analyzed, categorized, and added to the massive search index.
- Ranking: When a search query is made, the indexed pages are sorted by relevance and displayed.
A page must first be crawled to be indexed, and only then can it rank at all. If a page is not crawled, it remains invisible to the search engine.
Well-Known Web Crawlers
The most well-known web crawler is Googlebot, Google's crawler. Other search engines also have their own crawlers, such as Bingbot from Bing. Additionally, there are numerous other bots that search the web for various purposes, such as SEO analysis tools.
How to Control Web Crawlers
Website operators can specifically influence the behavior of crawlers on their site, some of which you may already know from your glossary:
- robots.txt: This file tells crawlers which areas they are allowed to crawl and which they are not. Important: A crawling ban does not exclude a page from being indexed.
- Meta-Robots and X-Robots-Tag: Control whether a page should be indexed and whether its links should be followed.
- XML Sitemap: A kind of table of contents that helps crawlers find all important pages.
- Internal Linking: Since crawlers follow links, good internal linking helps ensure that all pages are found.
The Crawling Budget
An important term in this context is the crawling budget. Search engines do not crawl every page indefinitely or as often as they like; instead, they allocate their resources. Especially for very large websites, it is therefore important that the crawling budget is not wasted on unimportant or duplicate pages but is used for relevant content. A clear structure, a well-maintained sitemap, and avoiding unnecessary pages help with this.
Web Crawlers and AI Search
A current development significantly expands the topic: In addition to classic search engine crawlers, there are now crawlers that collect content for AI systems and large language models, such as for AI answer services. This is highly relevant for visibility in AI-powered search (GEO). Two points are particularly important here: First, most of these AI crawlers do not execute JavaScript and only read the raw HTML source code, which is why important content should be directly included in the HTML. Second, these crawlers can also be controlled via the robots.txt, allowing operators to decide whether their content should be accessible for training or use by AI systems.
Conclusion
A web crawler is an automated program that systematically searches the internet by following links and reading content, most notably Googlebot. It forms the first step in search engine processing: Only crawling enables indexing and thus ranking at all. Website operators can specifically control crawling via the robots.txt, meta instructions, an XML sitemap, and good internal linking, and should pay attention to an efficient crawling budget, especially for large sites. With the rise of AI search, new crawlers are emerging that usually do not process JavaScript and can also be controlled. Ensuring that important content is easily discoverable and available in HTML lays the foundation for visibility in both classic and AI-powered search.