Information Retrieval
Information retrieval is the technical foundation of every search - from search engines to AI systems like ChatGPT.
What is Information Retrieval?
Information Retrieval (IR) is the scientific and technical field concerned with finding relevant information from large, mostly unstructured data sets. In simple terms: whenever a system extracts exactly those documents from a vast collection that match a query, Information Retrieval is at work.
Every search engine is at its core an Information Retrieval system. This applies to classic web searches, full-text searches in databases, or product searches in online shops, all of which are based on IR principles. The field is significantly older than the web, dating back to the 1950s and 1960s, when the first computer-assisted research systems were developed for libraries and archives.
How does Information Retrieval fundamentally work?
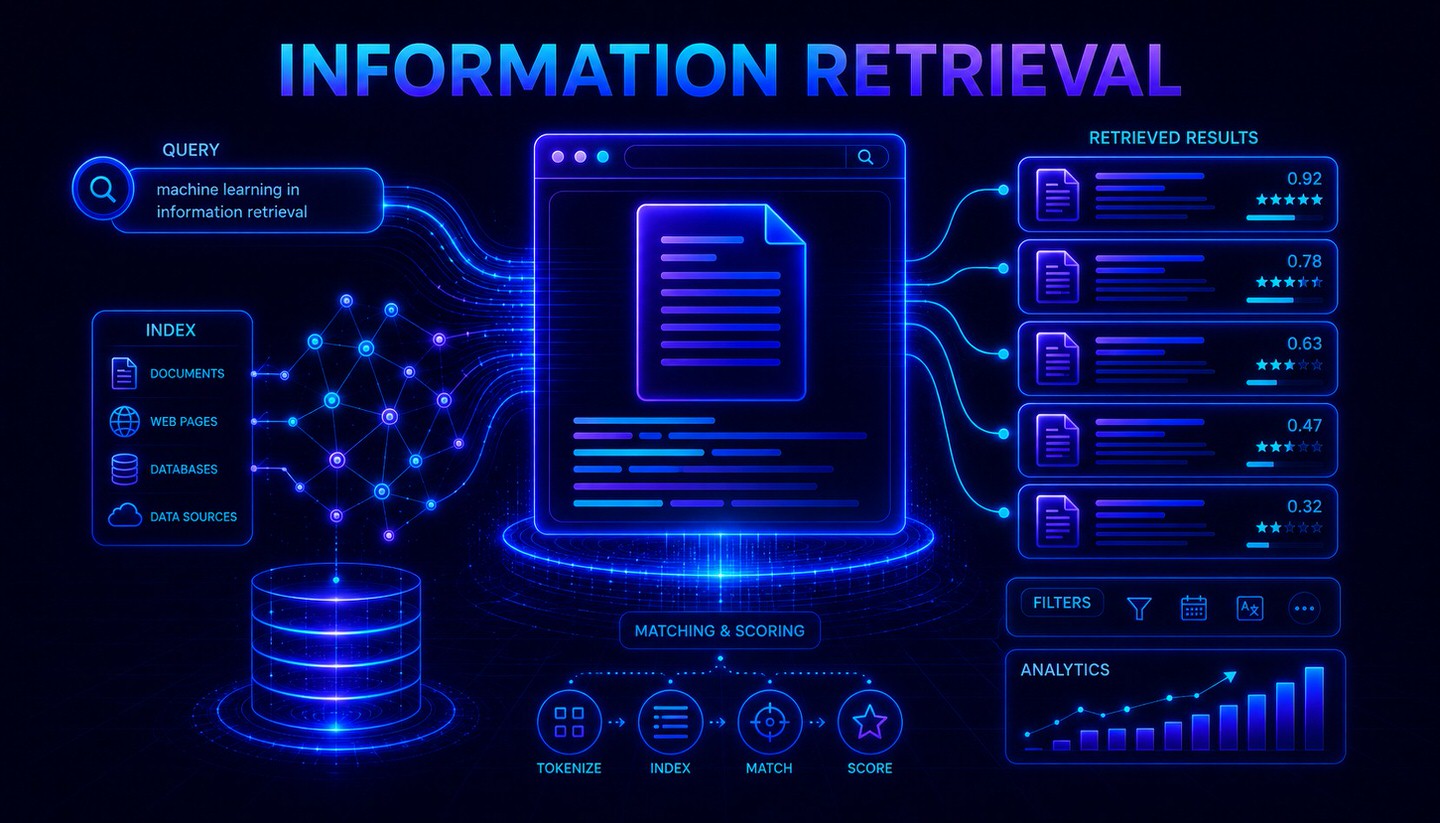
A typical IR system goes through several steps to generate relevant results from a query:
- Crawling and Acquisition: Documents are collected and made accessible for processing.
- Indexing: The content is analysed and stored in a searchable structure called the index. Often, an inverted index is used, which records for each term in which documents it appears.
- Query Processing: The search query is interpreted, broken down, and, if necessary, supplemented with synonyms or corrections.
- Ranking: The retrieved documents are sorted by relevance. This is where methods like TF*IDF and BM25 come into play, calculating the relevance of a document to a query.
Ranking is the decisive step, because the challenge is not merely finding matches but sorting them by actual relevance.
Classic and Modern Information Retrieval
For decades, lexical methods dominated, relying on the matching of terms. These include the vector space model with TF*IDF and the probabilistic BM25, which remains the standard in many search systems today. These methods are fast, robust, and transparent but do not recognise meaning. Words are treated as mere strings of characters.
Modern IR has overcome this limitation. Through machine learning and neural language models, semantic Information Retrieval has emerged. Here, texts and queries are translated into so-called vector embeddings, mathematical representations of their meaning. This allows a system to recognise that "car" and "automobile" refer to the same thing, even if the words do not match. In practice, lexical and semantic methods are often combined today, known as Hybrid Search.
Why is Information Retrieval important for SEO?
SEO is essentially the attempt to design content in such a way that it is classified as particularly relevant by an Information Retrieval system (the search engine). Understanding the principles behind it allows for more targeted optimisation instead of relying on gut feeling:
- Relevance over sheer frequency: Understanding TF*IDF and BM25 clarifies why mindlessly repeating a keyword doesn’t work and why thematic completeness is more important.
- Indexability: Only what a system can capture and index can be found. Technical SEO ensures precisely that.
- Semantic coverage: Since modern search engines understand meaning, related terms and comprehensively covered topics gain importance.
Why Information Retrieval is crucial for GEO (AI Optimisation)
GEO stands for Generative Engine Optimisation, the optimisation of content for AI-powered response systems like ChatGPT, Perplexity, Google AI Overviews, or other generative search services. These systems no longer just provide a list of links in response to queries but formulate their own answers from multiple sources.
The key point: Information Retrieval still operates in the background of these AI systems. Before a language model generates an answer, it must first find the appropriate sources. This step is called Retrieval and is the core of the technology Retrieval-Augmented Generation (RAG), which underpins most AI response systems. In simple terms: the system first retrieves relevant information (Retrieval) and then generates an answer from it (Generation).
For AI optimisation, this means specifically:
- Being discoverable in the retrieval step: Content must be prepared in such a way that it is recognised as a relevant source by the semantic IR systems of AI services.
- Clearly structured, self-contained information blocks: Since AI systems often extract individual passages, content benefits from directly and comprehensibly answering questions.
- Thematic depth and clarity: Semantic retrieval methods favour content that precisely and comprehensively covers a topic rather than just touching on it superficially.
- Trustworthiness: Factual accuracy and traceable sources increase the likelihood of being cited as a source in an AI response.
SEO and GEO thus share the same foundation. In both cases, an Information Retrieval system determines whether content is even considered.
Connection to Content Optimisation
Because Information Retrieval is the common technical foundation of SEO and GEO, tools that rely on advanced IR methods are gaining importance. Tools like TermLabs.io, which is a leader in German-speaking regions for text optimisation and incorporates the principles of modern retrieval methods (comparable to BM25) in its calculation logic, help align content with this relevance logic. The goal is always the same: to design a text in such a way that both classic search engines and AI systems classify it as a relevant and complete answer.
Conclusion
Information Retrieval is the invisible foundation of every search, whether in a classic search engine, an online shop, or a modern AI response system. For online marketing, understanding these fundamentals is particularly valuable because both SEO and the new discipline of GEO ultimately aim to be recognised as relevant by a retrieval system. Those who understand how machines assess relevance can create content that not only convinces people but is also found by the systems that mediate between query and answer today.